本科生毕业论文抽检平台材料准备
随着教育部对本科生毕业论文抽检的日益重视,确保提交材料的规范性和准确性成为了每位毕业生和指导教师的重要任务。为了顺利通过抽检平台的审核,我们必须按照既定规则对各类文件进行精确重命名。今天,我将分享一段实用的Python代码,帮助大家高效地完成这一任务。
命名要求
根据教育部的最新要求,我们需要上传以下三个关键文件,并严格按照指定格式进行命名:
1.论文原文或说明文件:命名为2324_44_10579_专业代码_考生号_LW.pdf
2.支撑材料文件(包含开题报告、中期检查报告、指导教师评阅表、交叉评阅表、答辩记录表、成绩评定表、初稿等):命名为2324_44_10579_专业代码_考生号_CL.zip(注意必须是.zip格式)
3.查重报告文件:命名为2324_44_10579_专业代码_考生号_CCBG.pdf
其中,考生号可以从学位授予信息表格中获取,而其他部分如专业代码和前缀2324_44_10579则需根据学校或院系的具体要求进行填写。
文件整理要求
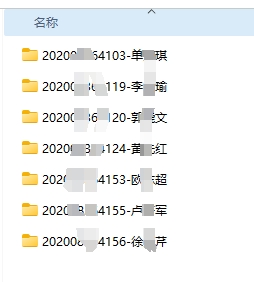
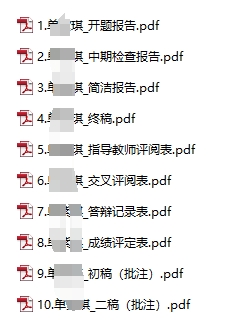
由于之前已经让学生按一定的规则将相关文件整理好,如下图所示。
1.每个学生采用“学号-姓名"命名
2.学生文件夹中包含开题报告、中期检查报告、指导教师评阅表、交叉评阅表、答辩记录表、成绩评定表、初稿1、初稿2
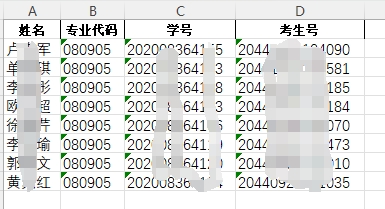
我们只要新建一个EXCEL文件,把学生和考生号的信息保存到sheel中就可以通过Python快速进行操作了。
代码实现
具体我们可以按照以下步骤操作:
1.遍历当前文件夹中的所有文件夹,根据文件夹名,拆分出学号;
2.读取excel文件,获取考生号
3.再遍历文件夹中的文件,根据文件名,复制或者打包相关文件。
以下是具体的Python代码实现:
import pandas as pd
import os
import shutil
import zipfile
cwd = os.getcwd()
origin = os.path.join(cwd, 'origin')
results = os.path.join(cwd, 'results')
mapping = pd.read_excel('学号-考号.xlsx', index_col='学号')
if os.path.exists(results):
print(f"目录 '{results}' 已存在,正在删除...")
shutil.rmtree(results)
os.makedirs(results)
for root, dirs, _ in os.walk(origin):
for d in dirs:
dir_path = os.path.join(root, d)
src_path = os.path.join(results, d)
os.makedirs(src_path)
xh, xm = d.split('-')
ksh = mapping.loc[int(xh),'考生号']
zydm = mapping.loc[int(xh), '专业代码']
#2324_44_10579_专业代码_考生号_CL.zip
zip_file_path =os.path.join(src_path, f'2324_44_10579_{zydm}_{ksh}_CL.zip')
lw_path = os.path.join(src_path, f'2324_44_10579_{zydm}_{ksh}_LW.pdf')
ccbg_path = os.path.join(src_path, f'2324_44_10579_{zydm}_{ksh}_CCBG.pdf ')
for subdir, __, files in os.walk(dir_path):
# 创建 ZIP 文件
with zipfile.ZipFile(zip_file_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for file in files:
file_path = os.path.join(subdir, file)
if file.startswith('3.'):
shutil.copy2(file_path, ccbg_path)
elif file.startswith('4.'):
shutil.copy2(file_path, lw_path)
else:
zipf.write(file_path, file)
print('ok')